We are making python script that scrape github repository URL and make a report of it on Excel File.
We are gonna learn to make web scraper and write the result on structured data file, in this case xlsx file.
Overview
On the first step, we are getting our repository list (pinned only).
- URL format:
https://github.com/{YOUR_GITHUB_USERNAME}?tab=repositories&q=&type=source. - Example:
https://github.com/encode?q=&type=source&language=.
From this URL page, we collect ULR repositories to be crawled, to collect repository data. Table below is the report table will look like:
| Repository | Created | Issues | Pull Request |
|---|---|---|---|
| String | Datetime String | Integer | Integer |
| String 2 | Datetime String | Integer | Integer |
Preparation
Environment Setup
$ mkdir github_report
$ cd github_report
# Set python virtual environment
$ virtualenv -ppython3 venv
# Load env
$ source venv/bin/activate
$ touch main.py requirements.txt
import argparse
GH_USER_URL = 'https://github.com/{GITHUB_USERNAME}?tab=repositories'\
'&q=&type=source'
GH_REPO_URL = 'https://github.com/{GITHUB_USERNAME}/{REPO_NAME}'
def get_pinned_repository(username: str):
"""collect listed repository list"""
result = []
return result
def get_repository_data(username: str, repo_name: str):
"""Collect repository data"""
def save_xlsx_report(repo_data_list: list):
"""Save repository data list to xlsx file"""
def get_html_content(url: str):
"""Get HTML Content from url or raise exception on error"""
def get_username() -> str:
"""Get github username from command list argument"""
parser = argparse.ArgumentParser("Github Report")
parser.add_argument('username')
args = parser.parse_args()
return args.username
def main(username: str):
"""Our main code logic"""
# Get pinned repo list
repo_list = get_pinned_repository(username)
len_repo_list = len(repo_list)
if len_repo_list == 0:
print(f'Pinned repository is empty')
return
print(f'got {len_repo_list} pinned repository: {repo_list}')
# Get repo data list
repo_data_list = []
for repo_name in repo_list:
repo_data = get_repository_data(username, repo_name)
print(f'repo_data: {repo_data}')
repo_data_list.append(repo_data)
if len_repo_list == 0:
print(f'Pinned repository is empty')
return
# Save to xlsx file
filename = save_xlsx_report(repo_data_list)
print(f'Report saved to: {filename}')
# main script entry
if __name__ == '__main__':
username = get_username()
main(username)
Usage
$ python main.py
usage: Github Report [-h] username
Github Report: error: the following arguments are required: username
Result Preview
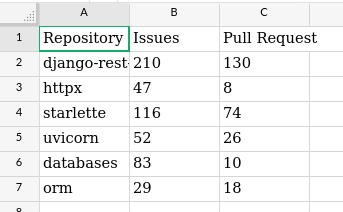
Tools
requirements.txt
beautifulsoup4
openpyxl
requests
Install python modules
$ pip install -r requirements.txt
Expanding Code
Github Repository Scraper (get_repository_list)
This function will access the URL and return HTML text content, if no error raised.
def get_html_content(url: str):
"""Get HTML Content from url or raise exception on error"""
response = requests.get(url)
# Raise exception if got error
response.raise_for_status()
html_text = response.text
# Make BeautifulSoup Nested data structure
return BeautifulSoup(html_text, 'html.parser')
Get Repository List (get_repository_list)
From HTML text, then scrape Repository list.
The pinned repo list is on span element and repo class.
def get_pinned_repository(username: str):
"""collect listed repository list"""
soup = get_html_content(
GH_USER_URL.format(GITHUB_USERNAME=username)
)
# find span elements, class="repo"
repo_spans = soup.find_all("span", class_="repo")
result = []
for repo in repo_spans:
result.append(repo.title)
return result
Get Repository Data (get_repository_data)
Next for repository data, we fetch issuess and pull requests number.
These data is on ul element and UnderlineNav-body list-style-none class. This li element contains 2 spans element. The first is for data name (‘Issues’ or ‘Pull requests’), another one for data number (E.q. Issues number).
def get_repository_data(username: str, repo_name: str):
"""Collect repository data"""
result = {'name': repo_name}
soup = get_html_content(GH_REPO_URL.format(
GITHUB_USERNAME=username, REPO_NAME=repo_name
))
ul = soup.find(
'ul', class_='UnderlineNav-body list-style-none'
)
for li in ul.find_all('li'):
spans = li.find_all('span')
if 'Issues' in spans[0].string:
result['issues'] = spans[1].string
if 'Pull requests' in spans[0].string:
result['pull_req'] = spans[1].string
return result
Write Excel File Using Openpyxl (save_xlsx_report)
Now we write the report with following format. First, we set table header, then iterate over repository data list.
def save_xlsx_report(repo_data_list: list):
"""Save repository data list to xlsx file"""
workbook = Workbook()
# Get active sheet
worksheet = workbook.active
# XSLX Header
# First row is for header
row = 1
headers = ['Repository', 'Issues', 'Pull Request']
columns = ['A', 'B', 'C']
for index, col in enumerate(columns):
cell = f'{col}{row}'
worksheet[cell] = headers[index]
for repo_data in repo_data_list:
row += 1
worksheet[f'A{row}'] = repo_data['name']
worksheet[f'B{row}'] = repo_data['issues']
worksheet[f'C{row}'] = repo_data['pull_req']
# Save excel file
filename = f"report.xlsx"
workbook.save(filename)
return filename
Info
This tutorial might help as introduction of Python Web Scraper for static web page. Although the html content of many website is dynamic (class or HTML element might change after reload). For this case, Python Selenium would help. by the way, more advance usage will challange you. Happy coding.